ERD for mysql
2024-11-19 graphviz graph diagram erd perl Template::Toolkit Parse::RecDescent HeidiSQLIn previous post I showed integration of Mermaid diagrams on my web pages. It reminded me of a script I found online and modified it for use with mysql and draw a little better diagrams than original script.
Lets take simple database to store Cost of Poor Quality (COPQ) entries. The group table contains organizational structure, departments, teams, and individuals. The rework table contains reworks caused by poor quality. The database was created directly on the server and then exported with HeidiSQL - result is following SQL dump:
-- --------------------------------------------------------
-- Host: srv01
-- Server version: 5.6.25-log - MySQL Community Server (GPL)
-- Server OS: Win64
-- HeidiSQL Version: 11.0.0.5919
-- --------------------------------------------------------
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET NAMES utf8 */;
/*!50503 SET NAMES utf8mb4 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
-- Dumping database structure for copq
CREATE DATABASE IF NOT EXISTS `copq` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `copq`;
-- Dumping structure for table copq.group
CREATE TABLE IF NOT EXISTS `group` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'Id',
`name` varchar(200) NOT NULL COMMENT 'Team/Group name',
`always_visible` tinyint(1) NOT NULL DEFAULT '0' COMMENT 'Should be always visible',
`active` tinyint(1) NOT NULL DEFAULT '1' COMMENT 'Active entry',
`parent_id` int(11) DEFAULT NULL COMMENT 'Parent team/person',
PRIMARY KEY (`id`),
KEY `FK_group_group` (`parent_id`),
CONSTRAINT `FK_group_group` FOREIGN KEY (`parent_id`) REFERENCES `group` (`id`) ON DELETE CASCADE ON UPDATE CASCADE
) ENGINE=InnoDB AUTO_INCREMENT=198 DEFAULT CHARSET=utf8;
-- Data exporting was unselected.
-- Dumping structure for table copq.rework
CREATE TABLE IF NOT EXISTS `rework` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'Id',
`date` datetime NOT NULL COMMENT 'When rework happened',
`program` varchar(256) NOT NULL COMMENT 'Program (C919, etc)',
`source` varchar(150) NOT NULL COMMENT 'Identification of the source (e.g. packet)',
`hours` decimal(10,2) NOT NULL COMMENT 'How much',
`penalty_hours` decimal(10,2) NOT NULL DEFAULT '0.00' COMMENT 'Penalty hours for re-review packets',
`group_id` int(11) NOT NULL COMMENT 'Person/Group responsible',
PRIMARY KEY (`id`),
UNIQUE KEY `source` (`source`),
KEY `FK_rework_group` (`group_id`),
CONSTRAINT `FK_rework_group` FOREIGN KEY (`group_id`) REFERENCES `group` (`id`) ON DELETE CASCADE ON UPDATE CASCADE
) ENGINE=InnoDB AUTO_INCREMENT=99677 DEFAULT CHARSET=utf8;
-- Data exporting was unselected.
/*!40101 SET SQL_MODE=IFNULL(@OLD_SQL_MODE, '') */;
/*!40014 SET FOREIGN_KEY_CHECKS=IF(@OLD_FOREIGN_KEY_CHECKS IS NULL, 1, @OLD_FOREIGN_KEY_CHECKS) */;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
The script below parses the input above and produces diagram below with tables, columns, and links created by foreign key constraints:
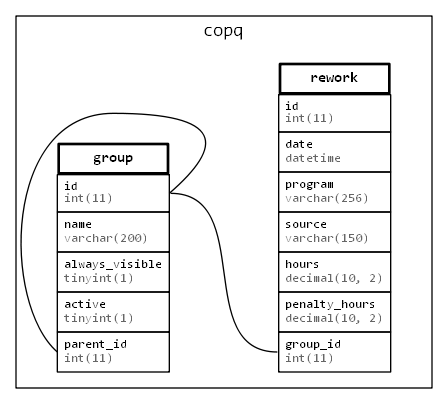
The script is as follows, based on Parse::RecDescent module grammar. All SQL except for CREATE TABLE is skipped and the gathered data is sent to graphviz via Template::Toolkit:
# create_erd.pl
#
# Copyright (C) 2004 Rene Nyffenegger
#
# This source code is provided 'as-is', without any express or implied
# warranty. In no event will the authors be held liable for any damages
# arising from the use of this software.
#
# Permission is granted to anyone to use this software for any purpose,
# including commercial applications, and to alter it and redistribute it
# freely, subject to the following restrictions:
#
# 1. The origin of this source code must not be misrepresented; you must not
# claim that you wrote the original source code. If you use this source code
# in a product, an acknowledgment in the product documentation would be
# appreciated but is not required.
#
# 2. Altered source versions must be plainly marked as such, and must not be
# misrepresented as being the original source code.
#
# 3. This notice may not be removed or altered from any source distribution.
#
# Rene Nyffenegger rene.nyffenegger@adp-gmbh.ch
#
################################################################################
# The original script came from: http://www.adp-gmbh.ch/perl/erd.html
#
# Modified by Roman Hubacek, May 25, 2009:
#
# - improved support of mysql DDL
# - removed comments, both /* */ and -- style
# - support for tags after CREATE TABLE
# - skips commands like SET or DROP, to allow for usage of mysqldump output
# - added IF NOT EXISTS clause
# - many mysql types (double, text, enum, timestamp and such)
# - out of line constraints added (KEY, FOREIGN KEY)
# - indirect references usually used by mysql
# - collations, encodings (only utf8_bin at the time)
# - numeric default, including floating-point
# - auto_increment columns
# - identifiers enclosed in ` (back apostrophe) support
# - comment on individual columns allowed
# - output format in dot
# - do not display 'constraint' columns
# - linking on indirect references
# - table represented by cluster to separate table name
# - types on second row
#
################################################################################
use 5.010; use strict; use warnings;
# make sure all packages are installed - needs ActivePerl for ppm
BEGIN {
my %check = (
'Parse::RecDescent' => 'Parse-RecDescent',
'Template::Plugin::Autoformat' => 'Template-Plugin-Autoformat',
'Template' => 'Template-Toolkit',
);
for my $mod (keys %check) {
eval "require $mod";
if($@) { system "ppm install $check{$mod}" }
}
}
use Parse::RecDescent;
use File::Basename;
use Template;
use Data::Dump qw{dump};
my $out_file_type = 'png';
$::RD_ERRORS = 1; # Make sure the parser dies when it encounters an error
$::RD_WARN = 1; # Enable warnings. This will warn on unused rules &c.
$::RD_HINT = 1; # Give out hints to help fix problems.
# $::RD_TRACE = 1; # Trace of parser (have Parse::RecDescent 1.96 or later to use on AS)
my $create_db_file = shift
or die "Usage: erd.pl schema.sql\n";
our $curr_database = "";
my $create_table_grammar = q{
create_table_stmts : create_table_stmt(s)
{ [ grep { 0 != scalar keys %$_ } @{$item[1]} ] }
create_table_stmt : /create/i /table/i if_not_exists(?)
table_name '(' rel_props cts_cont
{
warn '-- CREATE TABLE ',$item{table_name},"\n";
{ tab_nam => $item{table_name},
cols => $item{rel_props},
database => $::curr_database,
}
}
| /select|set|drop|create|insert/i token(s?) ';'
{ warn "skipped: ".join(" ",$item[1],@{$item[2]}),"\n"; {} }
| /use/i token(s?) ';'
{ $::curr_database = join(" ",@{$item[2]}); {} }
| ';'
{ {} }
| <error: Unknown SQL command>
token_pairs : token '=' token
| token
token : sql_string
| identifier
| /[^;]+/
cts_cont : ')' token_pairs(s?) /;?/i
if_not_exists : /if not exists/i
table_name : identifier
rel_props : columns # relational properties
columns : column ',' columns
{
if ($item[1]) { unshift @{$item[3]}, $item[1]}
else { print "xxx\n"};
$item[3]
}
| column
{ [ $item[1] ] }
column : out_of_line_constr
{
$return = {col_nam=> 'constraint'} ;
if(ref($item{out_of_line_constr}) eq "HASH") {
@{$return}{keys %{$item{out_of_line_constr}}}
= values %{$item{out_of_line_constr}}
}
}
| identifier reference_clause
{
$return = {col_nam=> $item{identifier}};
@{$return}{ keys %{$item{reference_clause}}}
= values %{$item{reference_clause}
}
}
| identifier data_type dt_constraint(s?)
{
{ col_nam => $item{identifier},
type => $item{data_type},
}
}
dt_constraint : null
| primary_key
| collate
| encoding
| default
| auto_increment
| on_clauses
| comment
comment : /comment/i sql_string
auto_increment : /auto_?increment/i
collate : /collate/i identifier
encoding : /character/i /set/i identifier
out_of_line_constr : named_const constraint
| constraint
named_const : /constraint/i identifier
constraint : /check/i paranthesis
| /unique/i paranthesis
| /unique/i /key/i identifier(?) index_type(?) paranthesis
| /primary/i /key/i index_type(?) col_name
{ { primary => $item{col_name} } }
| /foreign/i /key/i fk
{ $item[3] }
| /key/i identifier col_names index_type(?)
| /key/i identifier paranthesis index_type(?)
| /key/i paranthesis index_type(?)
index_type : /using/i /btree|hash/i
fk : col_name /references/i identifier col_name on_clauses(s?)
{
{ col => $item[1],
refd_table => $item[3],
refd_col => $item[4],
}
}
on_clauses : /on/i /delete|update/i /cascade|CURRENT_TIMESTAMP|no action|set null/i
col_names : '(' columns ')'
{ $item{columns} }
col_name : '(' identifier ')'
{ $item{identifier} }
paranthesis : '(' in_paranthesis ')'
{ $item{in_paranthesis} }
in_paranthesis : ( /[^()]+/ | paranthesis)(s)
reference_clause : /references/i identifier null(?)
{ { refd_table=>$item[2] } }
| data_type /references/i identifier null(?)
{
{ type => $item[1],
refd_table => $item[3],
}
}
default : /default/i default_value
default_value : sql_string
| number
| /b/ sql_string
| /null/i
| /CURRENT_TIMESTAMP/i
| <error: Bad default value>
sql_string : /'([^']|'')*'/
primary_key : /primary/i /key/i
null : not(?) /null/i
not : /not/i
data_type : dt_ident precision(?) signed(?)
{$item[1]. $item[2][0] || "" }
precision : '(' number ')'
{$item[1].$item[2].$item[3]}
| '(' number ',' number ')'
{$item[1].$item[2].$item[3].$item[4].$item[5]}
| paranthesis
{ ref($item[1]) eq "ARRAY" ? '('.join(",",@{$item[1]}).')'
: $item[1]
}
signed : /signed/i
| /unsigned/i
dt_ident : /number/i {$item[1]}
| /integer/i {$item[1]}
| /int +identity/i {$item[1]}
| /int/i {$item[1]}
| /tinyint/i {$item[1]}
| /decimal/i {$item[1]}
| /float/i {$item[1]}
| /double/i {$item[1]}
| /smallint/i {$item[1]}
| /long raw/i {$item[1]}
| /longblob/i {$item[1]}
| /longtext/i {$item[1]}
| /long/i {$item[1]}
| /varchar2/i {$item[1]}
| /varchar/i {$item[1]}
| /text/i {$item[1]}
| /char/i {$item[1]}
| /raw/i {$item[1]}
| /datetime/i {$item[1]}
| /timestamp/i {$item[1]}
| /date/i {$item[1]}
| /smalldatetime/i {$item[1]}
| /blob/i {$item[1]}
| /clob/i {$item[1]}
| /nclob/i {$item[1]}
| /bit/i {$item[1]}
| /boolean/i {$item[1]}
| /bool/i {$item[1]}
| /enum/i {$item[1]}
| <error: Unknown datatype>
number : /\d+(\.\d+)?/
{ $item[1] }
identifier : m(([\w.]+)|`(.+?)`)
{ $1 // $2 }
};
my $parser = Parse::RecDescent->new($create_table_grammar);
# load the input file
open my $fin, $create_db_file
or die "could not open $create_db_file";
my $string = do { local $/; <$fin> };
$string =~ s{/\*.*?\*/}{}gs;
$string =~ s{--.*?\n}{}gs;
my $result = $parser->create_table_stmts($string)
or die "could'n parse $create_db_file";
# init template engine
my $tool_dir = dirname($0);
$tool_dir =~ tr{\\}{/};
my $template = Template->new({ INCLUDE_PATH => $tool_dir });
open my $DOT, "|dot.exe -T$out_file_type > $create_db_file.$out_file_type";
# open my $DOT, ">","$create_db_file.dot";
my @refs;
foreach my $table (@$result) {
my $table_name = uc $table->{tab_nam};
my %col_by_name = ();
for my $col (@{$table->{cols}}) {
if ($col->{col_nam} eq 'constraint') {
if ( defined $col->{primary}
&& defined $col_by_name{$col->{primary}})
{
$col_by_name{$col->{primary}}->{primary} = 1;
}
if (defined $col->{refd_table}) {
push @refs, {
from_tbl => $table_name,
from_id => "i" . $col->{col},
to_tbl => uc $col->{refd_table},
to_id => "i" . $col->{refd_col},
};
}
next;
}
$col_by_name{$col->{col_nam}} = $col;
if (exists $col->{refd_table}
and uc $col->{refd_table} ne $table_name)
{
push @refs, {
from_tbl => $table_name,
from_id => "i" . $col->{col_nam},
to_tbl => uc $col->{refd_table},
};
}
}
}
my $databases = {};
for my $table (@$result) {
if(! defined $databases->{$table->{database}}) {
$databases->{$table->{database}} = [];
}
push @{$databases->{$table->{database}}}, $table;
}
$template->process(
'dot_table_graph_html.dot',
{ tables => $result,
databases => $databases,
refs => [@refs],
},
$DOT
) || die $template->error();
close $DOT;
warn "\nOutput written as \"$create_db_file.$out_file_type\"\n";
The dot_table_graph_html.dot template looks like this:
[% USE Autoformat %]
[% font = 'Consolas' %]
digraph erd {
rankdir=RL;
node [shape=plaintext,fillcolor=white,fontname="[% font %]",width=1.8,style=filled,fontsize=9];
edge [arrowhead=none,arrowtail=crow];
graph [fontname="[% font %]"];
[% i = 0 %]
[% FOREACH database IN databases.keys %]
subgraph cluster_[% i = i+1; i %] {
label="[% database %]";
[% FOREACH table IN databases.$database %]
"[% table.tab_nam | upper %]" [ shape="plaintext", label=<
<table border="0" cellspacing="0" cellpadding="4">
<tr><td border="2" bgcolor="white"><font face="[% font %] Bold" point-size="11">[% table.tab_nam %]</font></td></tr>
[%- FOREACH col IN table.cols -%]
[%- NEXT IF col.col_nam == 'constraint' -%]
<tr><td border="1" balign="left" align="left" port="i[% col.col_nam | html %]">
[%- "<font face=\"${font} Bold\">" IF col.primary -%]
[%- col.col_nam | html -%]
[%- '</font>' IF col.primary -%]<br/><font color="gray40">
[%-
col.type | replace('<','') | replace('>','') | replace(',',', ')
| Autoformat(right => 25)
| trim | replace('\n','<br/>')
-%]</font></td></tr>
[%- END -%]
</table>
> ];
[%- END %]
}
[% END %]
[% FOREACH ref IN refs -%]
"[%- ref.from_tbl %]":"[% ref.from_id %]":w -> "[% ref.to_tbl %]"[% ":\"$ref.to_id\"" IF ref.defined('to_id') %]:e;
[% END %]
}